[Tensorflow] 06. 순환 신경망 & LSTM
RNN(Recurrent Neural Network)은
시계열 또는 순차 데이터를 예측하는 딥러닝을 위한 신경망 아키텍처
입니다.

위 그림은 Single Layer와 Multi Layer Perceptron 구조를 보여준다. 일반적으로 완전 밀집 계층(Fully connected layers, 위 사진)의 경우 데이터의 흐름이 입력 층에서 은닉층을 거쳐 출력 층으로 단방향 이동을 거치게 된다. 허나, 이런 구조에서는 첫번째로 들어온 입력이 두번째로 들어온 입력과 별개의 case로 동작하게 된다.
그렇다면 시간이나 순서가 존재하는 데이터(자연어, 음성, 영상 등)의 입력은 어떻게 처리할까? 이를 위해 현재 입력값의 결과를 다음 입력값에 반영하는 RNN 구조를 이용한다.
RNN 뉴런은 입력데이터를 처리하여 결과값(Yt)을 도출하고 다음 time step의 자기 자신에게 연산한 결과값(Wt)을 전달한다. 자신에게 전달된 y값은 다음 결과값을 처리하는데에 반영된다. 이렇게 Sequence가 있는 데이터를 일괄적으로 기억하여 (context 파악) 출력값을 전달하게 된다.
LSTM
허나, RNN은 반복되는 계산으로 기울기가 0에 가까워지는 기울기 소멸(Vanishing Gradient) 문제가 쉽게 발생하게 된다. 극복하기 위해 여러가지 방법이 많이 나왔지만 이번 챕터는 LSTM을 이용한다.
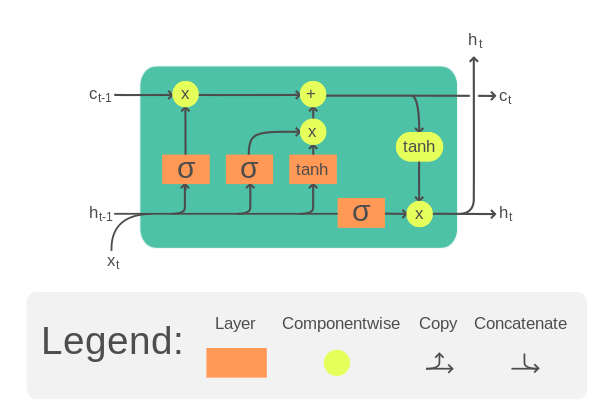
LSTM은 input gate, output gate, forget gate로 이루어진 셀이다. 각 게이트의 연산값을 이용하여 기울기 소멸 문제를 감소시키는 등 기존의 RNN에서 개량된 형태를 갖추고 있다.

위 그림은 정방향 및 역방향을 가진 양방향 LSTM을 보여주고 있다. 역방향 학습이 필요한 이유는 명확하다. 아래 문장을 보면,
1. 엄청난 괴력을 자랑하는 형사 마석도와 반장 전일만은 도시를 휘어잡은 신흥범죄조직의 보스 장첸을 비롯한 도시의 범죄조직을 일망타진할 작전을 세우기 시작한다.
2. 형사들과 주민들의 합동작전과 더불어 마석도와 장첸의 일대일 격돌이 펼쳐진다.2번 문장에서 '마석도'와 '장첸'이 극중 어떤 역할인지 알기위해서는 1번 문장의 '형사 마석도', '신흥범죄조직의 보스 장첸'이라는 정보를 가져와야한다. 즉, 뒤쪽 문장의 정보 해석을 위해 앞쪽 문장을 참조하는 역방향 학습이 필요한 것이다.
RNN으로 텍스트 분류기 만들기
04. 자연어처리 - Tokenizer와 05. 자연어처리 - Embedding에 쓰였던 Sarcasm 데이터를 그대로 이용합니다. 데이터 전처리 과정이 궁금하다면 해당 포스트를 참조하시길 바랍니다.
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(embedding_dim))), # 양방향 LSTM 이용
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
adam = tf.keras.optimizers.Adam(learning_rate=0.00001,
beta_1=0.9, beta_2=0.999, amsgrad=False)
model.compile(loss='binary_crossentropy',
optimizer=adam, metrics=['accuracy'])
history = model.fit(training_padded, training_labels, epochs=100,
validation_data=(testing_padded, testing_labels))
괜찮은 성능을 보이지만 하나의 LSTM 층을 사용하는 대신, Stacking LSTM을 사용하면 더욱 성능을 늘릴 수 있을 것으로 보인다.
Stacking RNN으로 텍스트 분류기 만들기
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(embedding_dim,
return_sequences=True)), # LSTM끼리는 Sequence를 전달해야 함
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(embedding_dim)),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
adam = tf.keras.optimizers.Adam(learning_rate=0.00001,
beta_1=0.9, beta_2=0.999, amsgrad=False)
model.compile(loss='binary_crossentropy',
optimizer=adam, metrics=['accuracy'])
history = model.fit(training_padded, training_labels, epochs=100,
validation_data=(testing_padded, testing_labels))첫번째 LSTM 레이어를 보면 return_sequences=True임을 알 수 있는데, 이는 다음 LSTM 레이어에 시퀀스로 넘겨주기 위함이다.

그래프를 보면 Single LSTM에 비해 Validation 정확도가 빠르게 올라가는 것을 알 수 있다. 하지만, Overfitting의 가능성이 보인다. 하이퍼 파라미터를 개선하면 더 좋은 결과가 나올 것으로 기대된다.